SPAM detection using fastai ULMFiT - Part 1: Language Model
tl;dr: 👉 show me the code! 🔥 here 🔥

UPDATE Feb.21.2020 Part 2, the classification model, is here
Non-technical introduction
Imagine you are a lawyer, that wants to study medicine; although it is a huge change, the underlying idea is you know how to speak in English, know the semantics to create a text, and the language rules.
So when you jump into medicine, you don't have to learn from scratch that after the word "They", it comes the word "were" (not "was").
You only learn the particularities of the domain field (medicine).
But what is ULMFiT? 📚🤖
ULMFiT stands for Universal Language Model Fine-tuning, and its implementation is in fastai pythons library.
Why is it useful? 🤔
It allows us to save time when creating an NLP project, thanks to the transfer learning technique, we do only need to fine-tune the network to our data. Let's say, it learns the domain field words.
Especially handy if we don't have lots of data.

About google colab
Not new, but google colab is a tool that allows us to run notebook python projects using the GPUs from google servers. It's free!
This two-blog post series can be run in your browser, only by executing all the cells! Time to play :)
Besides running the uploaded version, you can copy the project directly to your google drive and do all the practice you want! (File -> Save a copy in drive)
Read more: Google Colab Free GPU Tutorial
Going more technical
The project is split into:
1- Create the language model
2- Create the classification model
The language model is what handles the word and semantics representations, and it can be chained to the classification model quickly.
I suggest you read Universal Language Model Fine-tuning for Text Classification. It was created by Jeremy Howard and Sebastian Rude.
ULMFit contains a network that was trained on a corpus of 103MM Wikipedia articles. So it already knows how to speak "neutral".
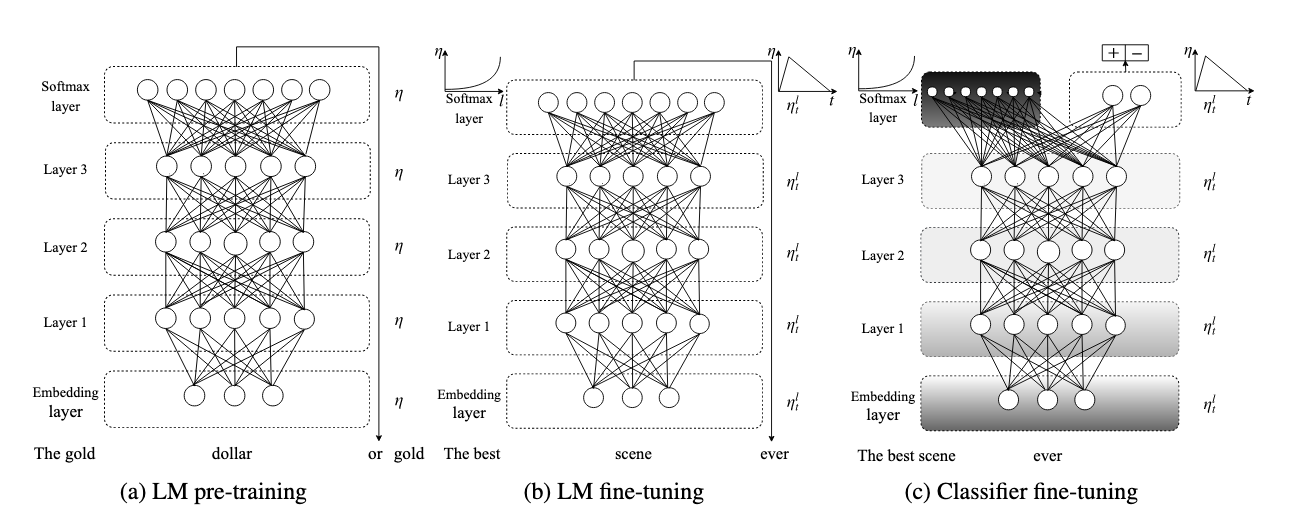
Source: arXiv:1801.06146v5
- Part 1: of this post is about section (a) and (b): Download pre-trained language model and do the fine-tuning with our data.
- Part 2: (c) create the classification model.
📚 Learn more from:
- Official web page: http://nlp.fast.ai/
- fastai youtube lesson: https://youtu.be/vnOpEwmtFJ8?t=4511 (it starts at ULMFiT stage)
Code 💻
This blog post assumes you have some prior knowledge in deep learning. But if not, I encourage you to run all the projects and playing by doing little changes in the code, and see what happens!
Some of the topics covered in the google colab, are:
- Pretrained model advantages (transfer learning)
- ULMFiT in other languages? (other than English)
- What is an embedding?
- How to train a language model
--
📌 Run the project here 👉 google colab
UPDATE Feb.21.2020 Don't forget to check Part 2, the classification model, here
Have data fun! 🚀
📬 Find me at: Linkedin & Twitter.
Data Science Live Book 📗